Datové struktury
Datové struktury umožňují organizaci, správu a ukládání dat tak, aby bylo možné s nimi efektivně pracovat.
Datová struktura je způsob organizace dat v paměti počítače, aby byla data přístupná a efektivně zpracovatelná.
V Pythonu si ukážeme čtyři základní struktury – seznamy, slovníky, n-tice (tuples) a množiny (sets)

Zdroj obrázku: https://files.realpython.com/media/Python-Tricks-Chapter-on-Data-Structures_Watermarked.b5d9d86333c3.jpg
{kind=link}
Seznamy
Seznamy v Pythonu jsou uspořádané kolekce (pole), které mohou obsahovat prvky různých datových typů, včetně dalších seznamů.
Jsou flexibilní, umožňují přidávání, odebírání a změnu prvků.
Užitečné pro úlohy, kde potřebujeme dynamicky měnit velikost kolekce (zpracování seznamu položek získaných od uživatele nebo z externího zdroje).

Zdroj obrázku: https://files.realpython.com/media/Pythons-list-Built-in-Data-Type-A-Deep-Dive-With-Examples_Watermarked.1f6291ed72f5.jpg
{kind=link}
Vytvoření seznamu a přístup k prvkům
Seznam v Pythonu vytvoříme tak, že prvky oddělíme čárkami a umístíme je do hranatých závorek [].
seznam_cisel = [1, 2, 3, 4, 5]
jmena = ["Marie", "Daniel", "Lukáš"]
vnoreny_seznam = [1, 2, [3, 4, 5], ["sest", "sedm"]]
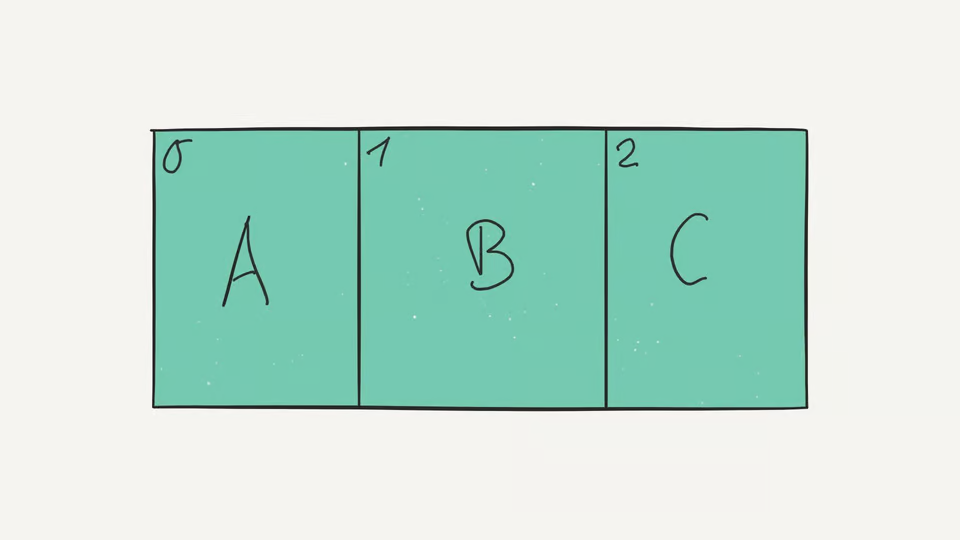
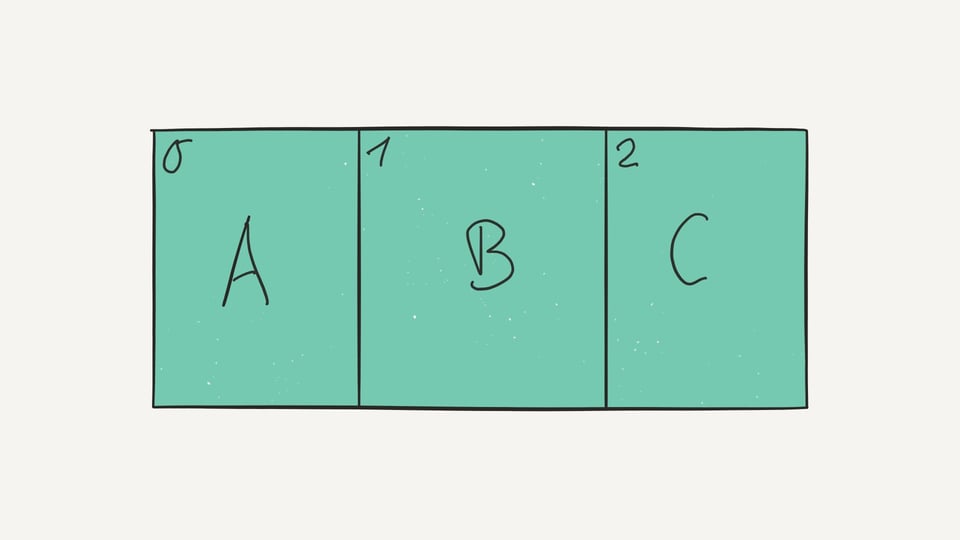
K prvkům v seznamu můžeme přistupovat pomocí indexování. Indexy začínají od nuly, takže prvek první prvek seznamu má index 0.
{kind=link}
print(jmena[0]) #Vypíše 'Marie'
print(vnoreny_seznam[2][1] #Vypíše '4', přistupuje k druhému prvku vnořeného seznamu
Modifikace seznamu
Seznamy můžeme měnit několika způsoby:
Přidání prvků
Používáme metody:
- append() – pro přidání prvku na konec seznamu
- insert() – pro vložení prvku na specifickou pozici
jmena.append("David")
jmena.insert(1, "Eva") # Vloží 'Eva' na index 1
Odstranění prvků
Používáme metody:
- remove() – pro odstranění prvního výskytu zadaného prvku
- pop(), pro odstranění prvku na určeném indexu (nebo poslední prvek, pokud nezadáme index)
jmena.remove("Daniel") # Odstraní 'Daniel'
jmena = jmena.pop(1) # Odstraní a vrátí prvek na indexu 1
Změna prvků
Můžeme změnit prvek na určitém indexu přiřazením nové hodnoty
jmena[0] = "Hana"
Metody pro práci se seznamy
- extend() – přidá prvky jednoho seznamu do jiného
- reverse() – obrátí pořadí prvků v seznamu
- sort() – seřadí prvky seznamu
- count() – vrací počet výskytů v seznamu
- index() – vrací index prvního výskytu hledané položky
jiny_seznam = [6, 7, 8]
muj_seznam.extend(jiny_seznam) # Rozšíří 'muj_seznam' o prvky z 'jiny_seznam'
muj_seznam.reverse() # Obrátí pořadí prvků
muj_seznam.count(5) # Spočítá počet pětek
muj_seznam.sort() # Seřadí prvky seznamu
muj_seznam.index(3) # Vrací index hledaného čísla '3'
Iterace přes seznam
Iterace přes prvky v seznamu provádíme pomocí for cyklu.
jmena = ["Marie", "Daniel", "Lukáš"]
for jmeno in jmena:
print(jmeno)
Tento skript projde celý seznam jmena, a vypíše pomocí for cyklu tato jména (obsah seznamu) na obrazovku.
Vyřezávání (slicing)
Pomocí vyřezávání můžeme získat podseznam z existujícího seznamu.
cisla = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
prvni_tri = cisla[:3] # Vezme první tři prvky
poslednich_pet = cisla[-5:] # Vezme posledních pět prvků
prostredek = cisla[3:7] # Vezme prvky od indexu 3 do 6 (index 7 není zahrnut)
Slovníky
Slovníky jsou klíč-hodnota páry, které jsou ideální pro přístup k datům přes klíč – to nám umožní rychlé vyhledávání, vkládání a mazání dat.
Slovníky jsou neuspořádané a klíče musí být jedinečné.
Používají se pro reprezentaci složitějších datových entit v aplikacích (konfigurační data, informace ve webových API).

Zdroj obrázku: https://files.realpython.com/media/How-to-Sort-a-Python-Dictionary_Watermarked.3615e3e40965.jpg
{kind=link}
Vytvoření slovníku a přístup k prvkům
Slovník v Pythonu vytvoříme pomocí složených závorek {}, kde prvky jsou odděleny čárkami a každý prvek se skládá z klíče a hodnoty oddělenými dvojtečkou.
osoba = {"jmeno": "Lukáš", "vek": 24, "obec": "Rakvice"}
K prvkům ve slovníku můžeme přistupovat pomocí klíče, který se umístí do hranatých závorek.
osoba = {"jmeno": "Lukáš", "vek": 24, "obec": "Rakvice"}
print(osoba["jmeno"]) #Vypíše Lukáš
Pokud se pokusíme přistoupit ke klíči, který ve slovníku není, Python vyhodí výjimku KeyError.
Pro bezpečnější přístup můžeme použít metodu get(), která vrátí hodnotu klíče, pokud existuje, nebo None (příp. jinou specifikovanou výchozí hodnotu), pokud klíč neexistuje.
osoba = {"jmeno": "Lukáš", "vek": 24, "obec": "Rakvice"}
print(osoba["jmeno"]) #Vypíše Lukáš
print(osoba.get("addresa")) # Vypíše 'None'
print(osoba.get("addresa", "Adresa nebyla specifikována")) # Vypíše 'Adresa nebyla specifikována'
Modifikace slovníku
Slovníky můžeme měnit několika způsoby:
Přidání nebo změna prvků
Přidání nového prvku nebo změna existujícího se provádí přiřazením hodnoty ke klíči.
osoba["vek"] = 31 # Změní stávající hodnotu klíče 'vek'
osoba["pohlavi"] = "muz" # Přidá nový klíč 'pohlavi' s hodnotou 'muz'
Odstranění prvků
Prvek lze odstranit pomocí klíčového slova del nebo metodou pop(), která odstraní prvek a zároveň vrátí jeho hodnotu.
del osoba["obec"] # Odstraní prvek s klíčem 'obec'
odstraneny_vek = osoba.pop("vek") # Odstraní 'vek' a vrátí jeho hodnotu
Metody pro práci se slovníky
- keys() – vrátí seznam klíčů ve slovníku
- values() – vrátí seznam hodnot ve slovníku
- items() – vrátí seznam dvojic klíč-hodnota ve slovníku
print(ososba.keys()) # Vypíše všechny klíče
print(osoba.values()) # Vypíše všechny hodnoty
print(osoba.items()) # Vypíše všechny dvojice klíč-hodnota
Iterace přes slovník
Iterace přes slovník může být prováděna přes klíče, hodnoty nebo přes obojí.
for key in osoba:
print(key, osoba[key]) # Vypíše klíče a hodnoty
for value in osoba.values():
print(value) # Vypíše hodnoty
for key, value in osoba.items():
print(key, value)
N-tice (Tuples)
N-tice jsou podobné seznamům, ale jsou neměnné (immutable).
To znamená, že jednou vytvořené n-tice nelze měnit.
Jsou rychlejší než seznamy a používají se pro ukládání dat, která se nemají měnit, například konfigurační nastavení nebo souřadnice bodů.
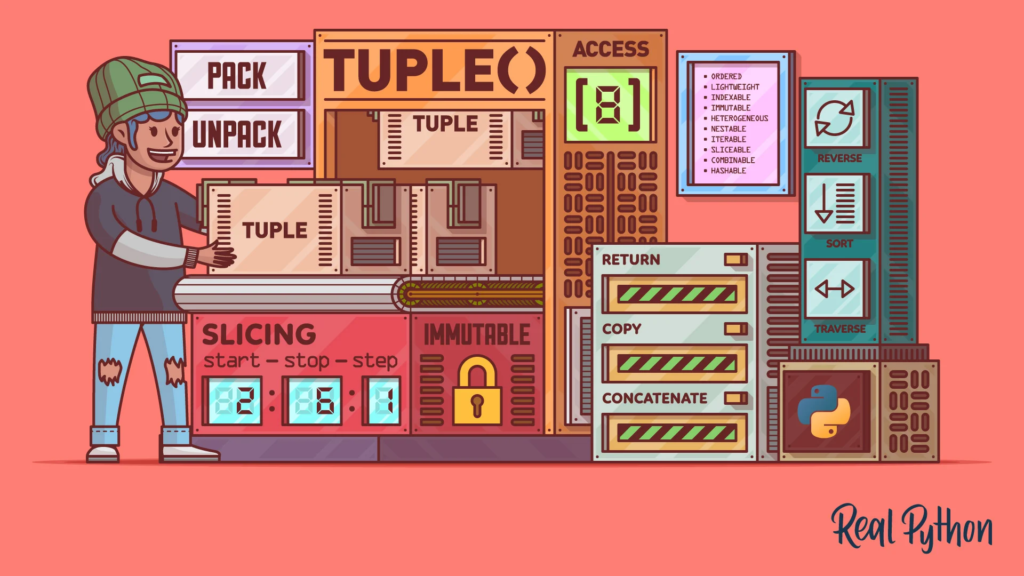
Zdroj obrázku: https://files.realpython.com/media/Pythons-tuple-Built-in-Data-Type-A-Deep-Dive-with-Examples_Watermarked.e85efb14c955.jpg
{kind=link}
Vytvoření n-tice a přístup k prvkům
N-tici v Pythonu vytvoříme tak, že prvky oddělíme čárkami a umístíme je do kulatých závorek (), nebo i bez nich, což je obzvlášť užitečné pro krátké n-tice.
entice = (1, 2, 3, 4, 5)
jedno_prvkova_enitice = (1,) # Pozor na čárku, je nezbytná pro n-tice s jedním prvkem
jmenna_entice = "Alena", "Daniel", "Lukáš"
Přístup k prvkům n-tice je stejný jako u seznamů – pomocí indexování.
print(entice[0]) # Vypíše '1'
print(jmenna_entice[1]) # Vypíše 'Daniel'
Neměnnost n-tic
Klíčovou vlastností n-tic je jejich neměnnost.
Jakmile je n-tice vytvořena, její struktura a obsažené prvky již nelze změnit.
To z nich činí ideální volbu pro uložení dat, která se nemají měnit, a často se používají pro zajištění integrity dat.
Metody n-tic
Ačkoliv n-tice neumožňují modifikaci prvků, existují metody pro práci s nimi:
- count() – vrátí počet výskytů dané hodnoty v n-tici
- index() – vrátí index prvního výskytu dané hodnoty
entice = (1, 2, 3, 4, 3, 3, 5)
print(entice.count(3)) # Vypíše '3' (počet trojek)
print(entice.index(4)) # Vypíše '3' (index první čtyřky)
Množiny (Sets)
Množiny jsou neuspořádané kolekce jedinečných prvků.
Jsou užitečné pro odstraňování duplikátů z dat a pro matematické operace jako sjednocení, průnik, rozdíl atd.
Díky svým matematickým operacím jsou také užitečné v situacích, kde potřebujeme provádět operace nad unikátními sadami prvků, jako jsou databázové dotazy nebo algoritmy pro zpracování dat.
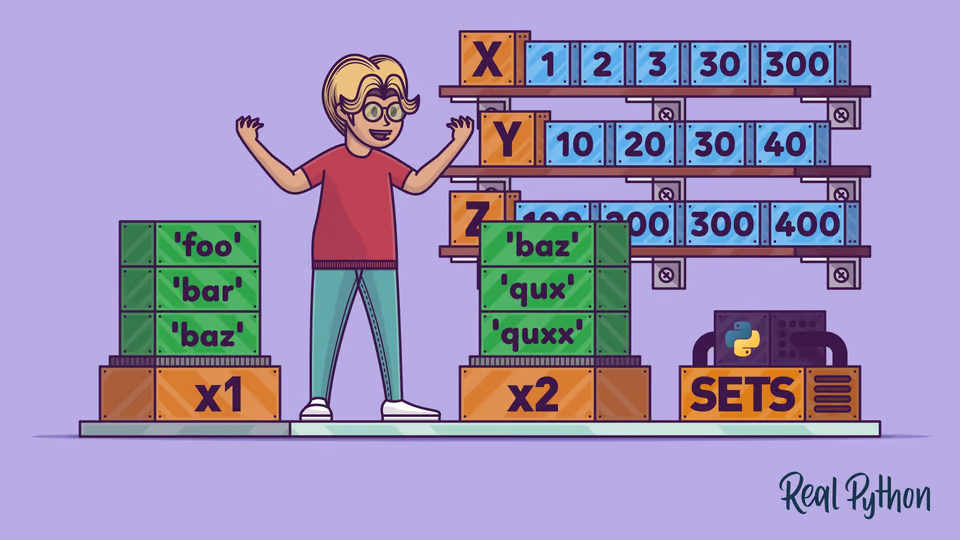
{kind=link}
Vytváření a základní operace
Množinu můžeme vytvořit pomocí složených závorek {} nebo pomocí funkce set().
Prázdnou množinu musíme vytvořit pomocí set(), protože prázdné složené závorky {} vytvoří prázdný slovník.
mnozina = {1, 2, 3, 4, 5}
jina_mnozina = set([2, 3, 5, 7, 11])
prazdna_mnozina = set()
Metody
- add() – pro přidání prvků do množiny
- remove() – pro odstranění prvků z množiny, pokud nenalezen – vyvolá výjimku
- discard() -pro odstranění prvků z množiny, pokud nenalezen – nevyvolá výjimku
mnozina.add(6) # Přidá prvek 6
mnozina.remove(6) # Odstraní prvek 6
mnozina.discard(7) # Odstraní prvek 7, pokud existuje, jinak nic nedělá
Matematické operace s množinami
Množiny podporují několik matematických operací, které reflektují základní množinové operace známé z matematiky:
- sjednocení (union) – vrátí množinu všech prvků z obou množin
- průnik (intersection) – vrátí množinu prvků, které se nacházejí ve všech množinách
- rozdíl (difference) – vrátí množinu prvků, které jsou v jedné množině, ale ne v druhé
- symetrický rozdíl (symmetric_difference) – vrátí množinu prvků, které jsou v jedné nebo druhé množině, ale ne v obou
mnozina_a = {1, 2, 3, 4}
mnozina_b = {3, 4, 5, 6}
sjednoceni = mnozina_a.union(mnozina_b) # Sjednocení, {1, 2, 3, 4, 5, 6}
prunik = mnozina_a.intersection(mnozina_b) # Průnik, {3, 4}
rozdil = mnozina_a.difference(mnozina_b) # Rozdíl, {1, 2}
symetricky_rozdil = mnozina_a.symmetric_difference(mnozina_b) # Symetrický rozdíl, {1, 2, 5, 6}
Iterace a testování členství
Iterace přes množinu je podobná iteraci přes seznam nebo n-tici, ale vzhledem k neuspořádané povaze množin není pořadí prvků zaručeno.
for prvek in mnozina:
print(prvek)
Pro testování, zda prvek patří do množiny, můžeme použít operátor in, který je velmi efektivní.
if 1 in mnozina:
print("1 je v množině")
Zdroje
Seznam zdrojů
itnetwork.cz. Online. Dostupné z: https://www.itnetwork.cz/.
w3schools.com. Online. Dostupné z: https://www.w3schools.com/.
Python 3 documentation. Online. Dostupné z: https://docs.python.org/3/
SMOLKA, Pavel. Programovací jazyk Python [online]. Mendelova univerzita v Brně, 2019. Dostupné z: https://emendelu.publi.cz/book/771-programovaci-jazyk-python-pruvodce-studiem
ŠVEC, Jan. Učebnice jazyka Python (aneb Létající cirkus) [online]. 2002. Dostupné z: https://i.iinfo.cz/files/root/k/Ucebnice_jazyka_Python.pdf
PILGRIM, Mark. Ponořme se do Python(u) 3: Dive into Python 3. CZ.NIC. Praha: CZ.NIC, c2010. ISBN 978-80-904248-2-1.
PECINOVSKÝ, Rudolf. Python: kompletní příručka jazyka pro verzi 3.11. Knihovna programátora (Grada). Praha: Grada Publishing, 2023. ISBN 978-80-271-3891-3.
Další zdroje (Youtube, obrázky) jsou vždy uvedeny.